4 篇论文被 ACM MM 2026 接收。
4 papers are accepted by ACM MM 2026.
张文涛,北京大学国际机器学习研究中心助理教授、研究员、博士生导师,Data-Centric AI Group 负责人。博士毕业于北京大学并师从崔斌教授,曾任职于腾讯机器学习平台部、Apple AIML 和加拿大 Mila 人工智能实验室。主要研究方向为以数据为中心的人工智能、LLM 数据系统、数据治理智能体与 AI4Science,聚焦大模型时代的数据基础设施,探索可复用、可扩展、可验证的下一代 AI 基础设施。
近五年以第一作者或通讯作者发表 CCF-A 类论文 100 余篇,谷歌学术引用逾 14,000+ 次,入选 Elsevier 世界前 2% 顶尖科学家,2026 年位列 CSRanking 北大 AI/ML 方向及 AI+Data 方向学者首位。现任 NeurIPS、ACL、SIGKDD 等国际会议领域主席,主持国家自然科学基金、科技部、教育部、北京市科委及校企合作科研项目 20 余项。
曾获广东省科技进步特等奖、中国电子学会科技进步一等奖、世界互联网大会领先科技成果奖,三次获得最佳论文奖:WWW 2022、APWeb 2023、CIKM 2024。入选智源学者、浦江青年学者、ACM SIGMOD China 新星奖、世界人工智能大会云帆奖等。课题组构建 DataFlow、MinerU、MinerU-HTML、DataFlex、AgentFlow、OpenWorldLib、One-Eval、Paper2Any 等开源系统,形成面向 Data-Centric AI 的系统化工具链和基础设施。
Wentao Zhang is an Assistant Professor, Researcher, and PhD Advisor at Peking University, leading the Data-Centric AI Group. He received his PhD from PKU under Prof. Bin Cui and previously worked at Tencent ML Platform, Apple AIML, and Mila. His research focuses on Data-Centric AI, LLM data systems, data governance agents, and AI4Science, building reusable, scalable, and verifiable data infrastructure for next-generation models.
In the past five years, he has published 100+ CCF-A papers as first or corresponding author, with 14,000+ Google Scholar citations, and has been selected among Elsevier's top 2% scientists worldwide. In 2026, he ranks #1 among PKU scholars in AI/ML and AI+Data on CSRankings. He serves as Area Chair for NeurIPS, ACL, and SIGKDD, and has led 20+ research projects from NSFC, MOST, MOE, Beijing municipal programs, and industry collaborations.
He has received the Special Prize of Guangdong Science and Technology Progress Award, the CIE Science and Technology Progress Award, and the World Internet Conference leading achievement award, with best-paper-level awards at WWW 2022, APWeb 2023, and CIKM 2024. His group builds open systems including DataFlow, MinerU, MinerU-HTML, DataFlex, AgentFlow, OpenWorldLib, One-Eval, and Paper2Any, forming a systematic toolchain and infrastructure for Data-Centric AI.
从大语言模型、多模态大模型,到 Agentic LLM 与 World Model,我们持续布局 Data Infra,目标是以更低成本、更低门槛和更高质量完成数据获取、解析、合成、清洗、评估与训练调度,让 Data-Centric AI 成为下一代模型能力增长的基础设施。
From LLMs and multimodal foundation models to agentic LLMs and world models, we continuously build Data Infra for lower-cost, lower-barrier, and higher-quality data acquisition, parsing, synthesis, cleaning, evaluation, and training orchestration, making Data-Centric AI a core infrastructure layer for next-generation model capabilities.
4 篇论文被 ACM MM 2026 接收。
4 papers are accepted by ACM MM 2026.
1 篇论文被 COLM 2026 接收:Variational Co-Evolution via Reinforcement Learning。
One paper is accepted by COLM 2026: Variational Co-Evolution via Reinforcement Learning.
1 篇论文被 IEEE TPAMI 接收:Aligning Condensed Graph via Hashing: A New Insight for Federated Graph Learning。
One paper is accepted by IEEE TPAMI: Aligning Condensed Graph via Hashing: A New Insight for Federated Graph Learning.
获 广东省科技进步特等奖。
Awarded the Special Prize of Guangdong Science and Technology Progress Award.
4 篇论文被 ECCV 2026 接收:MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding、Scientific Image Synthesis: Benchmarking, Methodologies, and Downstream Utility、Concept-as-Tree: A Controllable Synthetic Data Framework Makes Stronger Personalized VLMs、GRAN-TED: Generating Robust, Aligned, and Nuanced Text Embedding for Diffusion Models。
Four papers are accepted by ECCV 2026: MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding, Scientific Image Synthesis: Benchmarking, Methodologies, and Downstream Utility, Concept-as-Tree: A Controllable Synthetic Data Framework Makes Stronger Personalized VLMs, and GRAN-TED: Generating Robust, Aligned, and Nuanced Text Embedding for Diffusion Models.
4 Papers are accepted by ICML 2026.
3 篇论文被 SIGKDD 2026 接收:RARE: Retrieval-Augmented Reasoning Modeling、Dripper: Token-Efficient Main HTML Extraction with a Lightweight LM、ProfiliTable: Profiling-Driven Tabular Data Processing via Agentic Workflows。
Three papers are accepted by SIGKDD 2026: RARE: Retrieval-Augmented Reasoning Modeling, Dripper: Token-Efficient Main HTML Extraction with a Lightweight LM, and ProfiliTable: Profiling-Driven Tabular Data Processing via Agentic Workflows.
1 篇论文被 VLDB 2026 接收:QA-GraphRAG: Query-Adaptive Plug-and-Play Retrieval Integration for Graph-based Retrieval-Augmented Generation。
One paper is accepted by VLDB 2026: QA-GraphRAG: Query-Adaptive Plug-and-Play Retrieval Integration for Graph-based Retrieval-Augmented Generation.
1 Papers is accepted by ACL 2026 Industry Track.
11 Papers are accepted by ACL 2026 Findings.
8 Papers are accepted by ACL 2026 MainConference.
获评 浦江青年学者。
Awarded Pujiang Young Scholar.
Two Papers are accepted by ICDE 2026.
Five Papers are accepted by CVPR 2026.
获评 智源学者。
Awarded Zhiyuan Scholar.
博士生徐铭浩获 腾讯青云奖学金。
PhD student Minghao Xu received the Tencent Qingyun Scholarship.
Six Papers are accepted by ICLR 2026.
Two Papers are accepted by WWW 2026.
One Paper is accepted by SIGKDD 2026.
Two Papers are accepted by AAAI 2026.
Seven Papers are accepted by NeurIPS 2025.
Six Papers are accepted by EMNLP 2025.
🏆 We win the First Place Winner in ICML 2025 Challenges on Automated Math Reasoning and Extensions!
Five Papers are accepted by ACM MM 2025.
Two Papers are accepted by ICCV 2025.
One Paper is accepted by VLDB 2025.
One Paper is accepted by ECML 2025.
Six Papers are accepted by ACL 2025 Main.
One Paper is accepted by ACL 2025 Findings.
Three Papers are accepted by SIGKDD 2025.
One Paper is accepted by IEEE TKDE 2025.
Two Papers are accepted by ICML 2025.
One Paper is accepted by IJCAI 2025.
One Paper is accepted by ISSTA 2025.
One Paper is accepted by SIGIR 2025.
One Paper is accepted by ISSTA 2025.
Two papers are accepted by CVPR 2025.
One paper is accepted by ICDE 2025.
Two papers are accepted by IEEE TKDE 2025.
Four papers are accepted by ICLR 2025.
Two papers are accepted by ICDE 2025.
Two papers are accepted by WWW 2025.
One papers is accepted by VLDB 2025.
Two papers are accepted by AAAI 2025.
Two papers are accepted by ICDE 2025.
🏆 We win the Best Student Full Paper Award in CIKM 2024!
One paper is accepted by IEEE BIBM 2024.
Three papers are accepted by NeurIPS 2024.
One paper is accepted by CIKM 2024.
One paper is accepted by VLDB 2024.
One paper is accepted by SIGKDD 2024.
One paper is accepted by the main track of ACL 2024.
One paper is accepted by ICML 2024.
One paper is accepted by JMLR 2024.
One paper is accepted by TKDE 2024.
Four papers are accepted by ICDE 2024.
I am awared First Prize of Scientific and Technological Progress Award of CIE due to the Angel Project.
One paper is accepted by VLDB 2024.
One paper is accepted by SIGMOD 2024.
I am awared 2023 CAAI Doctoral Dissertation Award.
One paper is accepted by WWW 2024.
One paper is accepted by ACM Computing Survey 2024.
Two papers are accepted by ICLR 2024.
One paper is accepted by AAAI 2024.
I am awared 2023 Beijing Doctoral Dissertation Award.
Three papers are accepted by ICDE 2024.
One paper is accepted by ICDE 2024.
🏆 We win the Best Paper Runner Up Award in APWeb-WAIM 2023.
One paper is accepted by ACM Computing Survey 2023.
One paper is accepted by NeurIPS 2023.
One paper is accepted by VLDB 2024.
One paper is accepted by APWEB-WAIM 2023.
One paper is accepted by CIKM 2023.
Our book about Diffusion Model is now avaliable.
One paper is accepted by TKDE 2023.
One paper is accepted by SIGKDD 2023.
One paper is accepted by VLDB 2023.
One paper is accepted by SIGMOD 2023.
One paper is accepted by AAAI 2023.
One paper is accepted by ICDE 2023.
One paper is accepted by VLDBJ 2022.
One paper is accepted by NeurIPS 2022.
获世界人工智能大会 云帆奖-明日之星,2022。
Awarded Rising Star at the World AI Conference, 2022.
I am honor to present the valedictorian for the class of 2022 in CS of PKU.
I receive my Ph.D. degree in computer science from Peking University with Outstanding Doctoral Dissertation Award.
One paper is accepted by the journal VLDBJ 2022.
Four papers are accepted by the conference SIGKDD 2022.
Two papers as first author, have been accepted by ICML 2022.
One paper related to AutoML, has been accepted by Bioinformatics 2022.
🏆 We win the Best Student Paper Award in WWW 2022 !
We release our first version of the scalable graph learning toolkit--SGL.
One paper is selected as the Best Paper Award Nominees in WWW 2022. The corresponding PasCa system (integrated into SGL) will be open source next month!
One paper as corresponding author, related to GNN-based Recommendation, has been accepted by the journal ACM Computing Survey 2022 .
One paper related to graph-based recommendation, has been accepted by the conference ICDE 2022 .
One paper as first author, related to graph data annotation, has been accepted by the conference ICLR 2022 .
One paper related to our large scale Hyper-paramater Tuning system, has been accepted by the conference VLDB 2022 .
I accepted the invitation to serve as Program Committee member of the Research Track of ACM SIGKDD 2022.
One paper as first author, related to our scalable graph NAS system, has been accepted by the conference WWW 2022 .
Our OpenBox team won the “Outstanding Winner” at the openGCC contest in CCF ChinaSoft 2021. Congratulations!
Two papers as first author, related to scalable graph learning and graph data annotation, have been accepted by the conference NeurIPS 2021 with Spotlight (< 3%).
We propose GAMLP, a scalable and efficient graph model, which achieves the top #1 performance in three public and largest ogbn graphs (i.e., ogbn-papers100M, ogbn-products, and ogbn-mag)! See the leaderboards here.
One paper as first author, related to large-scale graph data selection, has been accepted by the conference VLDB 2021.
One paper as co-first author, related to deep GNN, has been accepted by the journal TKDE 2021.
One paper as third author, related to our AutoML system -- VocalnoML, has been accepted by the conference VLDB 2021.
Three papers, related to sparse graph, graph decomposition and our blackbox optimization (BBO) system -- OpenBox, are accepted by the conference SIGKDD 2021.
As the only person in China, I was selected as an Apple Scholar in AI/ML. Many thanks to Apple!
One paper as first author has been accepted by the conference SIGMOD 2021. Looking forward to the meeting in Xi'an this summer!
Context · Memory · Wiki · RAG / GraphRAG · Second Brain
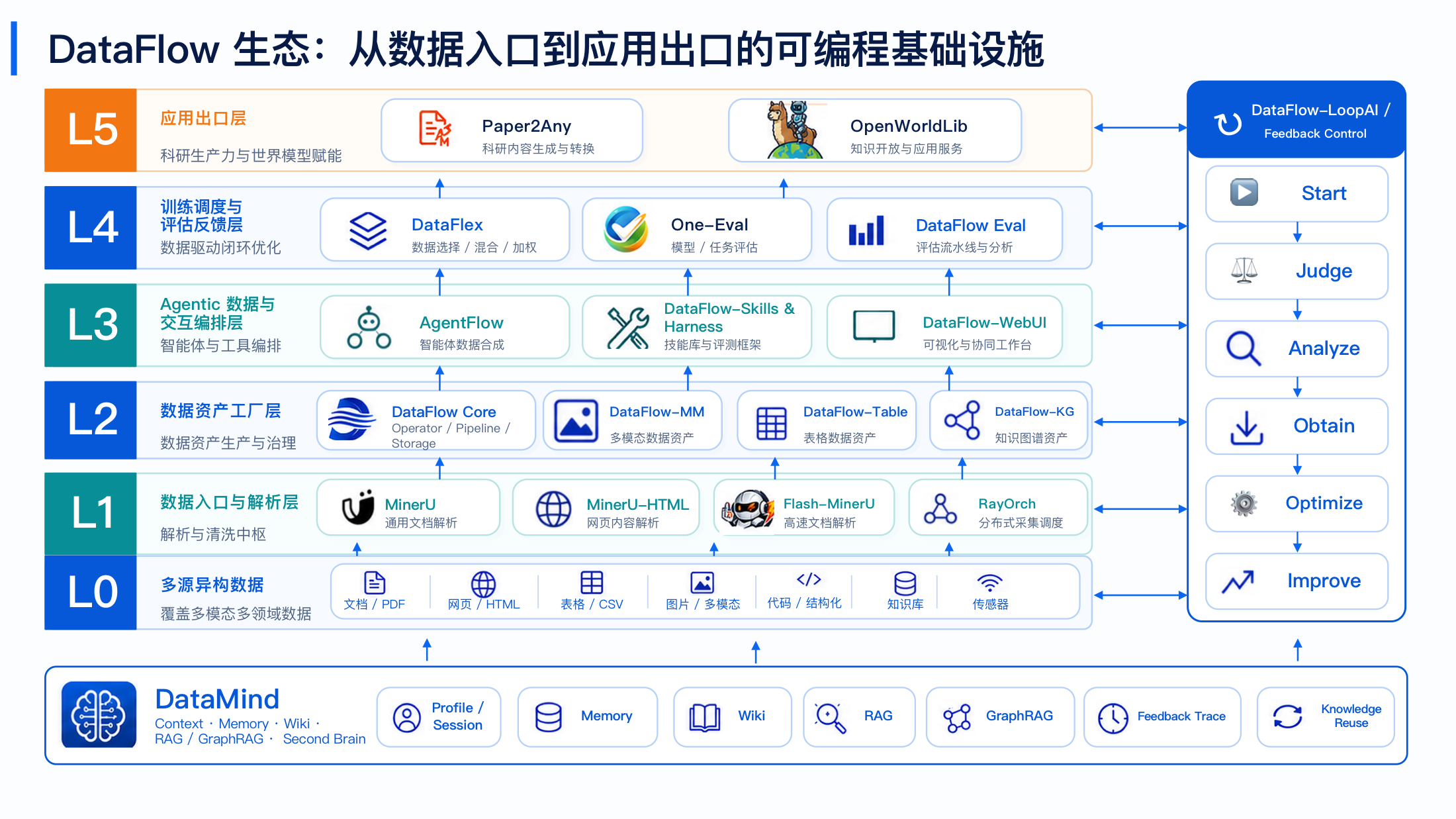
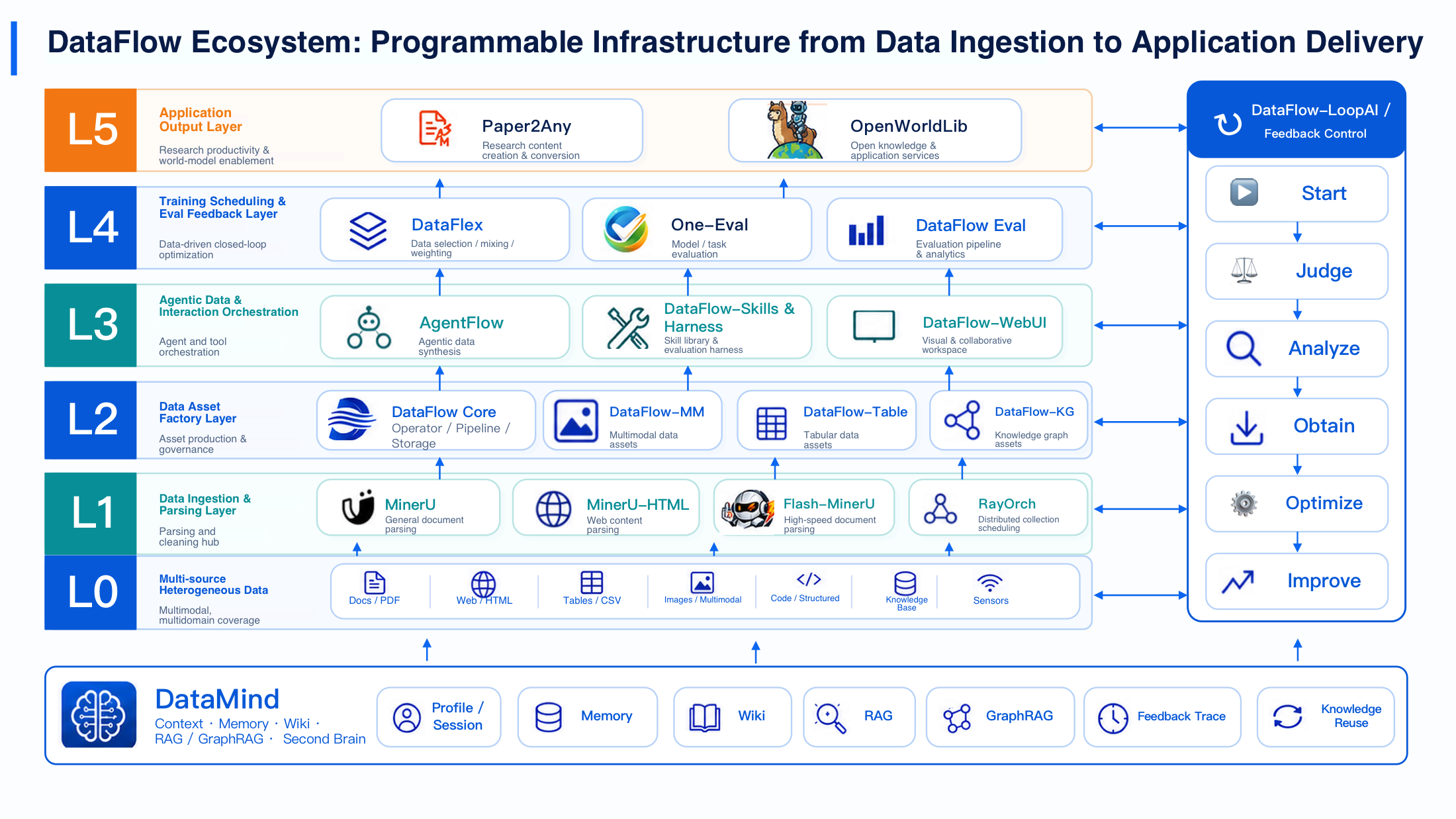
大模型数据准备系统,包含数据获取、处理、质量评估、算子和工作流编排。
LLM data preparation with acquisition, processing, quality evaluation, operators, and workflows.
通用文档解析引擎,将 PDF、图片和复杂版面转换为 AI-ready 文档数据。
General document parsing that converts PDFs, images, and complex layouts into AI-ready document data.
基于轻量语言模型的网页主内容抽取工具,服务高质量 HTML 数据清洗。
Lightweight-LM main-content extraction for high-quality HTML data cleaning.
训练过程中动态选择、配比和重加权数据的 Data-centric LLM 训练框架。
Data-centric LLM training with dynamic selection, mixture, and reweighting.
DataFlow 的多模态扩展,覆盖图像、视频、音频等数据资产的处理与评测。
The multimodal extension of DataFlow for image, video, audio, and related data assets.
面向大模型的闭环优化框架,从评测、问题分析到数据获取和训练反馈。
Closed-loop LLM optimization from evaluation and failure analysis to data acquisition and feedback.
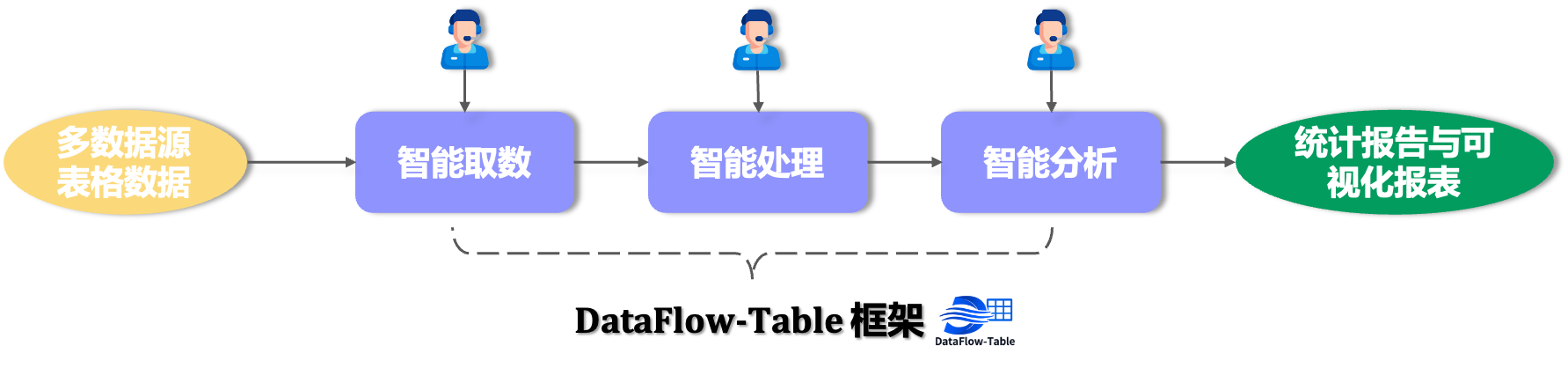
自动化表格数据处理框架,覆盖取数、处理和分析三类 Agentic Workflow。
Agentic workflows for table extraction, processing, and analysis.
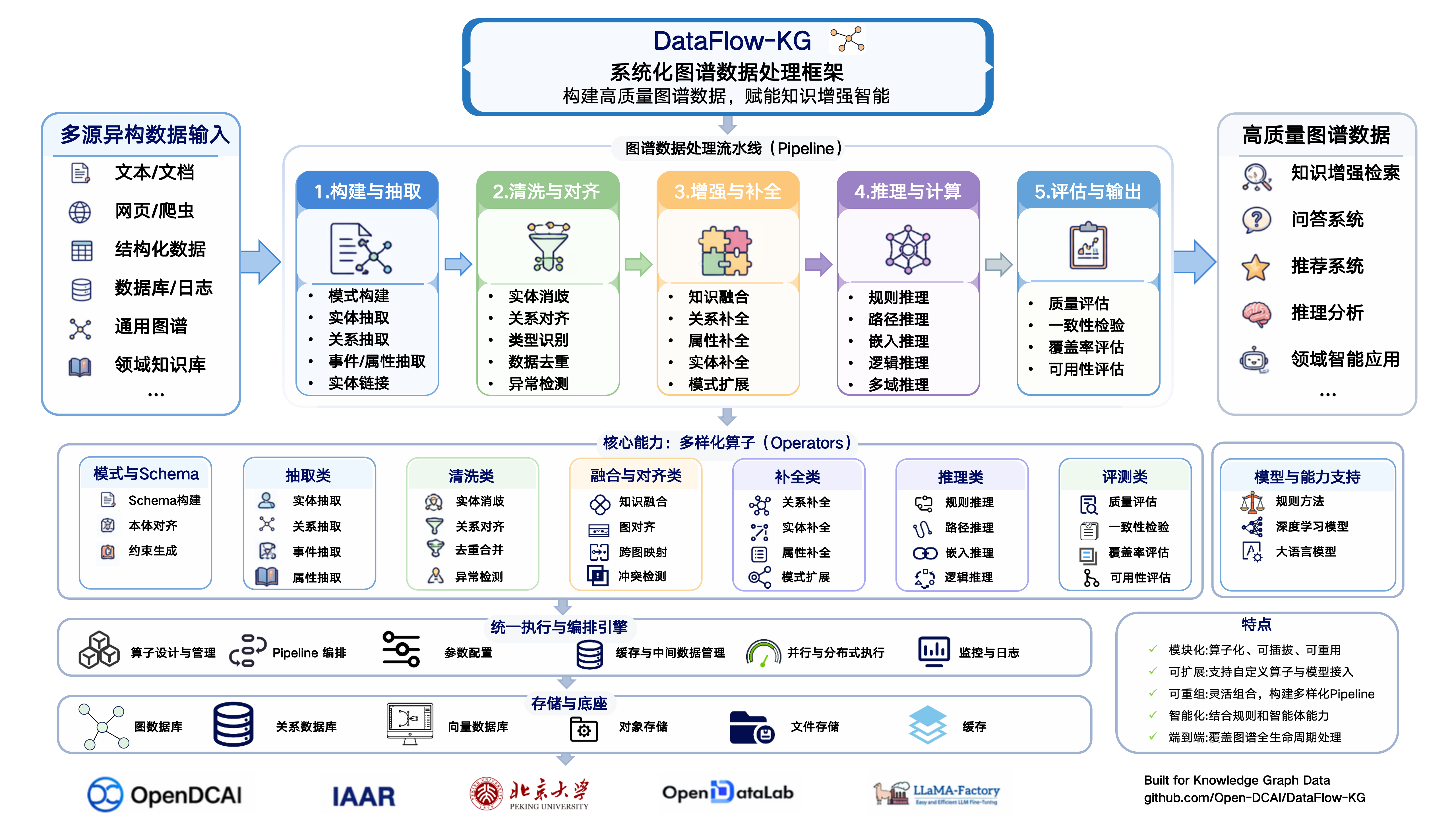
面向知识图谱数据处理的 DataFlow 扩展,支持图谱构建、补全、推理与评测。
DataFlow extension for knowledge graph construction, enrichment, reasoning, and evaluation.
将 DataFlow 扩展到 World Model 场景,支持世界模型数据准备与评估。
Extends DataFlow to world-model data preparation and evaluation.
自动化评测框架,目标是一句话从用户需求到模型评测报告。
Automated LLM evaluation from natural-language needs to model reports.
基于 DataFlow-Agent 搭建的科研资产生成应用,支持科研绘图、PPT、海报等。
Research asset generation for figures, slides, posters, and related workflows.

首个包含 RAG、MM-RAG、DeepResearch、Code、GUI 等多环境的 Agent 数据合成框架。
Agent data synthesis across RAG, MM-RAG, DeepResearch, Code, GUI, and more.
面向 DataFlow 生态的可复用技能库,把数据算子、流程生成和质量评测沉淀成可组合能力。
A reusable skill library for the DataFlow ecosystem, packaging data operators, workflow generation, and quality evaluation as composable capabilities.
面向大模型与智能体的 Memory OS,统一长期记忆的存储、检索、管理与个性化调用。
A Memory OS for LLMs and agents, unifying long-term memory storage, retrieval, management, and personalization.
腾讯与北大联合设计的高性能分布式机器学习与图计算平台。
A high-performance distributed machine learning and graph computing platform.

系统介绍大模型数据全生命周期管理,覆盖数据获取、清洗解析、标注、合成增强、质量评估、合规安全,以及 PDF 数据垂类模型微调实践。
A systematic book on the lifecycle of LLM data, covering acquisition, cleaning and parsing, annotation, synthesis, quality evaluation, compliance, safety, and PDF-data fine-tuning practice.
查看图书页面View book page
面向生成式 AI 与扩散模型的理论、应用和代码实践,介绍扩散模型基础、典型生成任务与前沿应用。
A book on diffusion-model theory, applications, and code practice for generative AI, covering foundations, representative generation tasks, and frontier applications.
查看图书页面View book page在当前高度竞争的 AI 人才生态中,无论是工业界顶尖计划,还是学术界 Top 课题组博士招生与教职聘任,核心竞争力已从“论文数量”转向“综合影响力”。我会从以下五个维度支持你的成长。
In today's competitive AI ecosystem, long-term competitiveness comes from integrated research impact rather than paper count alone. The group supports students across the following five dimensions.
聚焦真实需求与产业趋势,避免内卷赛道,例如 LLM Data、Data-Centric AI、数据智能体等方向。
We focus on real needs and industry trends, including LLM data, Data-Centric AI, and data agents.
CCF-A 顶会论文仍是重要门槛,但更看重工作是否被引用、被主流开源项目采纳、解决关键问题。
Top-tier papers remain important, but we care more about whether work is cited, adopted, and solves key problems.
主导或深度参与高星开源项目,建立工程与研究能力、形成个人品牌,围绕核心项目构建研究骨架。
Students can lead or deeply contribute to high-impact open-source projects and build a research agenda around core systems.
鼓励学生进入头部企业或研究院实习,在真实场景、海量数据和强大算力中锤炼问题定义能力。
Students are encouraged to intern at leading companies and labs, learning from real scenarios, large-scale data, and strong compute.
课题组的学术网络、合作资源和学校平台将直接影响科研效率、合作机会与职业出口。
The group's academic network, collaborations, and PKU platform support research efficiency, opportunities, and career outcomes.
学生目前主要在以下企业、研究院和联合培养平台参与研究实习、项目合作与联合培养。
Students mainly participate in research internships, project collaborations, and joint training through the following companies, research institutes, and platforms.
依托北京大学国际机器学习研究中心招收博士生,也依托上海 AI Lab、北京中关村学院等平台招收联培博士生。申请 2027 年秋季入学博士/硕士的学生,建议先联系实习。
PhD and master students are welcome through PKU CMLR and joint programs with Shanghai AI Lab and Beijing Zhongguancun Academy. Students applying for Fall 2027 are encouraged to start with an internship.
长期招收博士后,与北京大学鄂维南院士和崔斌教授联合培养,方向包括大模型数据、Data-Centric AI、AI4Science 和智能体系统。
Long-term postdoc openings are available in LLM data, Data-Centric AI, AI4Science, and agent systems, jointly mentored with Prof. Weinan E and Prof. Bin Cui.
长期招收研究实习生,可远程/校外实习。适合希望参与 CCF-A 论文、开源系统建设、真实产业数据问题和科研产品化的学生。
Research interns are welcome year-round, including remote interns. This is suitable for students who want to work on CCF-A papers, open-source systems, real data problems, and research products.
 腾讯混元
腾讯混元 字节 Seed
字节 Seed 字节 TikTok
字节 TikTok 阿里 Qwen
阿里 Qwen 快手可灵
快手可灵 中关村学院
中关村学院 上海 AI Lab
上海 AI Lab Apple AIML
Apple AIML 微软 MSRA
微软 MSRA 北京智源
北京智源 蚂蚁
蚂蚁 Kimi
Kimi 阶跃星辰
阶跃星辰 华为
华为 小米
小米 美团 LongCat
美团 LongCat 三星
三星 九坤量化
九坤量化